반응형

2025년 3유형 체험환경 문제 풀이
유튜브 아답터 해설 강의 참고
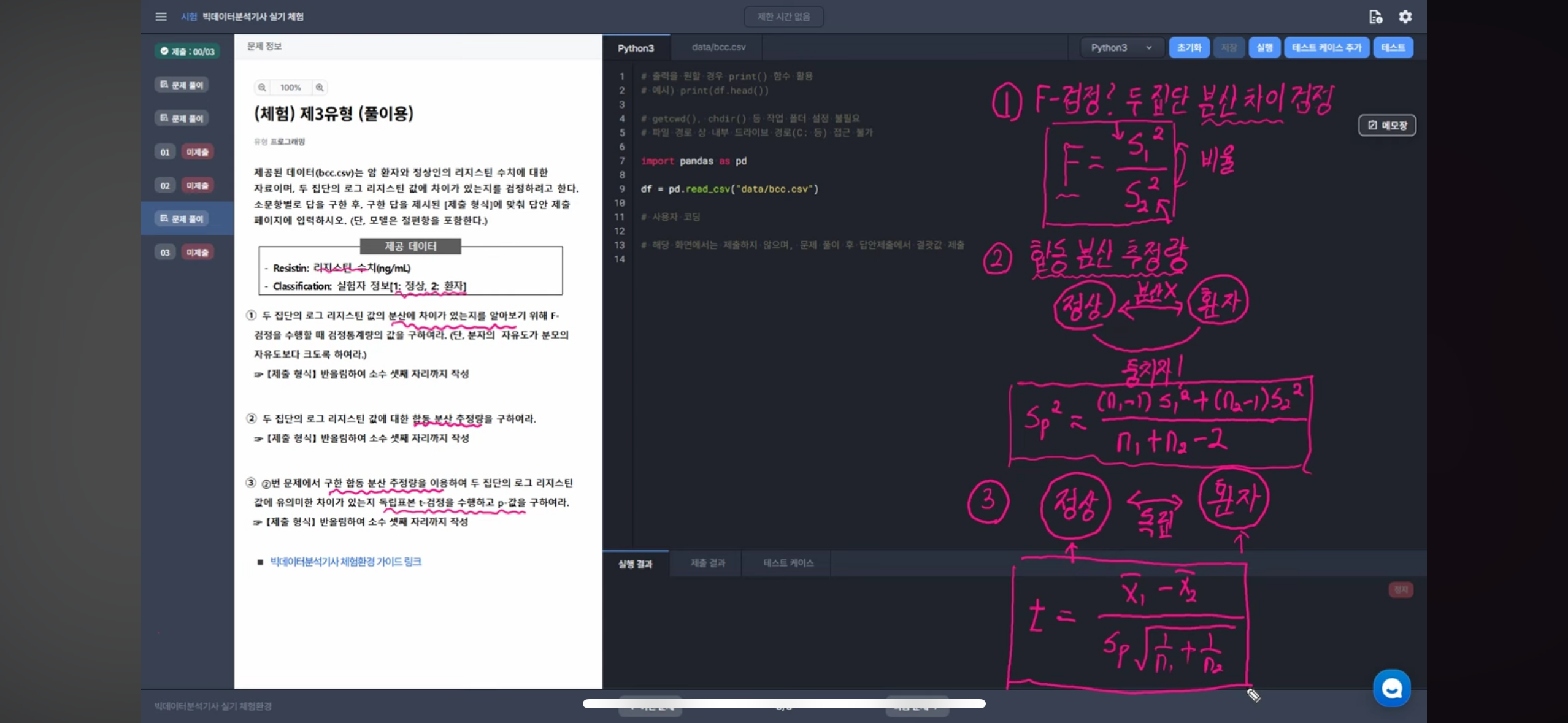
# 출력을 원할 경우 print() 함수 활용
# 예시) print(df.head())
# getcwd(), chdir() 등 작업 폴더 설정 불필요
# 파일 경로 상 내부 드라이브 경로(C: 등) 접근 불가
import pandas as pd
import numpy as np #넘파이 임포트 해주기
from scipy import stats
df = pd.read_csv("data/bcc.csv")
# 사용자 코딩
# 1번 문제
df['log_resistin'] = np.log(df['Resistin']) # 로그 구하기
group1 = df[df['Classification'] == 1]['log_resistin']
group2 = df[df['Classification'] == 2]['log_resistin']
var1 = group1.var()
var2 = group2.var()
# 자유도
dof_1 = len(group1)
dof_2 = len(group2)
print(dof_1, dof_2) # 52 64 분자가 더 커야하니까 2가 분자
f_stat = var2 / var1
print(round(f_stat, 3))
# 2번 문제
n1 = len(group1)
n2 = len(group2)
pooled_var = ((n1 - 1) * var1 + (n2 - 1) * var2) / (n1 + n2 - 2)
print(round(pooled_var, 3))
# 3번 문제
mean1 = group1.mean()
mean2 = group2.mean()
t_stat = (mean1 - mean2) / np.sqrt(pooled_var * (1/n1 + 1/n2))
# 누적밀도함수
# from scipy import stats
# print(dir(stats.t))
# p-value는 2 * (1 - stats.t.cdf(abs(t_stat), df= n1+ n2-2)
# 누적밀도 함수는 정규분포에서 왼쪽끝부터 오른쪽 t값까지 전체 밀도이기때문에 1에서 빼줘야함! 그리고 양측검정이기떄문에 *2를 해줌!
p_value = 2 * (1 - stats.t.cdf(abs(t_stat), df=n1+n2-2)) # 이건 걍 잊어버리기
print(round(p_value, 3))
##이렇게라도 풀면 3번에 (3)번 10점 받기 가능!
ttest_value = stats.ttest_ind(group1,group2,equal_var = True) #두 집단의 분산이 같다고 가정하는 경우 (기본값 True) 생략가능
print(ttest_value)
# 이거말고도 'ttest_1samp', 'ttest_ind', 'ttest_ind_from_stats', 'ttest_rel',
# 대응 : ttest_rel
# 단일표본(one sample) : ttest_1samp
# 독립표본 : ttest_ind
from scipy import stats
print(dir(stats))
# 해당 화면에서는 제출하지 않으며, 문제 풀이 후 답안제출에서 결괏값 제출
3유형 2024년도 체험환경 문제풀이
import pandas as pd
df = pd.read_csv("data/Titanic.csv")
# 1번
from scipy.stats import chi2_contingency
# 교차표 생성
table = pd.crosstab(df['gender'],df['Survived'])
statistics, p, df, expected = chi2_contigency(table)
print(round(statistics, 3)) # 260.717
#위 4가지는 뭘 받아오는지 일일이 외울수가없어서 바로 table 찍기
print(table)
# 268.717, 1.19, 1, array([..]) <- 검정통계량, p-value, 자유도 인것을 알수있음!!!!
# 카이제곱 범주형 : chi2_contigency
# 카이제곱 수치형 : chisquare
# t_테스트 단일검정 : ttest_1samp
# 독립표본 : ttest_ind
# 대응표본 : ttest_rel
# 2번
from statsmodels.api import Logit # Logit 대신 OLS 를 쓰면 선형회귀임!!!
formula = "Survived ~ Gender + SibSp Parch + Fare"
results = Logit.from_formula(formula, df).fit()
print(results.summary())
# 3번
# 오즈비는 계수에다가 wxponential 만 해주면 됨!!
import numpy as np
print(round(np.exp(-0.3539),3)
기출문제 8회 문제풀이
import pandas as pd
# df = pd.read_csv("churn.csv")
df = pd.read_csv("https://raw.githubusercontent.com/lovedlim/bigdata_analyst_cert/main/part4/ch8/churn.csv")
# 기출8회 3유형 문제풀이
# print(df.shape)
# 1번 (1)
# 로지스틱 회귀분석 0.05이상 유의하지않은 독립변수의 개수
# 방법: 포뮬라 생성 -> 로지스틱 회귀모델 학습fit -> p-value가 0.05 보다 큰 변수 개수 세기
# print(df.columns)
formula = "Churn ~ AccountWeeks + ContractRenewal + DataPlan + DataUsage + CustServCalls + DayMins + DayCalls + MonthlyCharge + OverageFee + RoamMins"
from statsmodels.formula.api import logit
# import statsmodels
# print(dir(statsmodels.formula.api))
model = logit(formula, data=df).fit()
# print(model.summary())
# intercept 제외하고 나머지중에 0.05 이상인것 8개임. 답 : 8개
# 1번(2)
formula = "Churn ~ DataUsage + DayMins "
model = logit(formula, df).fit()
print(model.summary())
print(round(sum(model.params))) # 상수항포함! params가 계수들인가봄.
# 1번(3)
# 오즈비는 무조건 계수의 Exp
import numpy as np
coef = model.params['DataUsage']
print(coef)
print(round(np.exp(-0.1697*5),3)) # 변수가 5 증가하면 오즈비는 exp(x * 5) 이거임
import pandas as pd
# df = pd.read_csv("churn.csv")
df = pd.read_csv("https://raw.githubusercontent.com/lovedlim/bigdata_analyst_cert/main/part4/ch8/churn.csv")
# 기출8회 3유형 문제풀이
# 2번(다중회귀)
import pandas as pd
# df = pd.read_csv("piq.csv")
df = pd.read_csv("https://raw.githubusercontent.com/lovedlim/bigdata_analyst_cert/main/part4/ch8/piq.csv")
# print(df.columns)
# 2 (1)
from statsmodels.formula.api import ols
formula = "PIQ ~ Brain + Height + Weight"
model = ols(formula, df).fit()
# print(model.summary())
# 답 : 2.343
# 2(2)
# print(round(model.rsquared, 3)) # <- 굳이 안쓰고 걍 써머리에서 보고 답 적어도됨
# 답 : 0.37
new = pd.DataFrame({'Brain' : [90], 'Height' : [70], 'Weight' : [150]})
# print(new)
pred = model.predict(new)
print(round(pred,3))
# 답 : 106
기출 9회 3유형
# 기출 9회 3유형
# 1번
import pandas as pd
# df = pd.read_csv("design.csv")
df = pd.read_csv("https://raw.githubusercontent.com/lovedlim/bigdata_analyst_cert_v2/main/part4/ch9/design.csv")
# print(df.shape)
# print(df.columns)
# print(df)
# (1)
train = df[df["id"] <= 140]
test = df[df["id"] > 140]
# print(train.shape,test.shape)
# print(df)
formula = "design ~ c1+c2+c3+c4+c5"
import statsmodels
# print(dir(statsmodels.formula))
from statsmodels.formula.api import ols
model = ols(formula,df).fit()
# print(model.summary())
# 답 : 3개
#(2)
formula = "design ~ c1 + c2 + c4"
model = ols(formula,train).fit() # df넣는거아님!!!
# print(model.summary())
train["pred_design"] = model.predict(train)
result = train['design'].corr(train['pred_design'], method='pearson') # corr() 안에 예측값을 넣는것임!!
# print(help(df.corr))
# print(round(result,3))
# (3)
# model = ols(formula,test).fit()
test["pred_design_test"] = model.predict(test)
from sklearn.metrics import root_mean_squared_error
rmse = root_mean_squared_error(test["pred_design_test"], test["design"])
# print(rmse)
# 기출 9회 3유형
# 2번
import pandas as pd
# df = pd.read_csv("retention.csv")
df = pd.read_csv("https://raw.githubusercontent.com/lovedlim/bigdata_analyst_cert_v2/main/part4/ch9/retention.csv")
# 로지스틱 순서
# formula 생성 -> logit 임포트 -> fit -> summary -> 오즈비는 exp (넘파이 임포트) -> 마지막 예측 predict()
# (1)
# print(df.columns)
formula = "Churn ~ MonthlyCharges + CustomerTenure + HasPhoneService + HasTechInsurance"
from statsmodels.formula.api import logit
model = logit(formula, df).fit()
# print(model.summary())
# 답 : 0.008
# (2) 오즈비
import numpy as np
oz2 = np.exp(model.params['HasPhoneService'])
# print(oz2)
# (3)
prob = model.predict(df)
print(prob)
print(sum(prob > 0.3))
7회
# 1번
import pandas as pd
# df = pd.read_csv("clam.csv")
df = pd.read_csv("https://raw.githubusercontent.com/lovedlim/bigdata_analyst_cert/main/part4/ch7/clam.csv")
# print(df)
#(1)
train = df[:210]
test = df[210:]
# print(test.shape)
from statsmodels.formula.api import logit
formula = "gender ~ weight"
model = logit(formula, train).fit()
# print(model)
import numpy as np
odds = np.exp(model.params["weight"])
# print(round(odds,4))
#(2)
# print(df.columns)
formula = "gender ~ age + length + diameter + height + weight"
model = logit(formula, train).fit()
# print(model.llf * (-2))
# 답 : 286.93
#(3)
from sklearn.metrics import accuracy_score
formula = "gender ~ weight"
model = logit(formula, train).fit()
pred = model.predict(test)
# 2번
# df = pd.read_csv("system_cpu.csv")
df = pd.read_csv("https://raw.githubusercontent.com/lovedlim/bigdata_analyst_cert/main/part4/ch7/system_cpu.csv")
# (1)
# print(df)
corr = df.corr()["ERP"]
# print(corr)
# 다른 풀이(전체 corr구하기)
corr_metrix = df.corr()
# print(corr_metrix)
erp_corr = corr_metrix["ERP"].sort_values(ascending = False)
# print(erp_corr) # Feature3
# (2)
# print(df)
df = df[df["CPU"] < 100]
formula = "ERP ~ Feature1 + Feature2 + Feature3 + CPU"
from statsmodels.formula.api import ols
model = ols(formula, df).fit()
print(model.summary()) # 0.755
# (3)
# 0.684
pred = (pred > 0.5).astype(int)
ac = accuracy_score(test['gender'], pred)
print(ac)
print(1-ac) # 0.478
반응형
'🙋 0. 문코딩 소개 > 0-3 자격증' 카테고리의 다른 글
| 빅데이터 분석 기사 실기 2유형 정리(2025년 2유형 체험 문제 + 기출문제 9~6회) (0) | 2025.06.20 |
|---|---|
| 빅데이터 분석 기사 실기 1유형 정리(2025년 1유형 체험 문제, 데이터마님 전처리 100문제 풀이) (0) | 2025.06.13 |
| [자격증] 제 10회 빅데이터분석기사 필기 시험 합격 후기 (0) | 2025.04.12 |
| [자격증] 정보처리기사 2022년 1회 실기 합격 후기 (7) | 2022.06.27 |
| [자격증] 컴활 1급 필기 하루 만에 따는 법 (0) | 2022.01.27 |




댓글